- Benchmarks: MP-DocVQA, SlideVQA, InfoVQA (VisRAG-style document images) plus reconstructed MultimodalQA and MMCoQA webpages; evaluated with R@3 and MRR@10 for retrieval, EM/F1 for end-to-end QA.
- Retrieval gains: LILaC (MM-Embed) sets the best R@3/MRR@10 across all five datasets—e.g., 69.07 / 75.28 on MultimodalQA (+10.34 R@3 over VisRAG-Ret) and 55.80 / 50.77 on MMCoQA (+28.17 R@3).
- QA accuracy: Paired with Qwen2.5-VL 7B, LILaC delivers the highest F1 on every benchmark (e.g., 51.97 on MultimodalQA, 43.22 on MMCoQA) while staying competitive on VisRAG-style datasets.
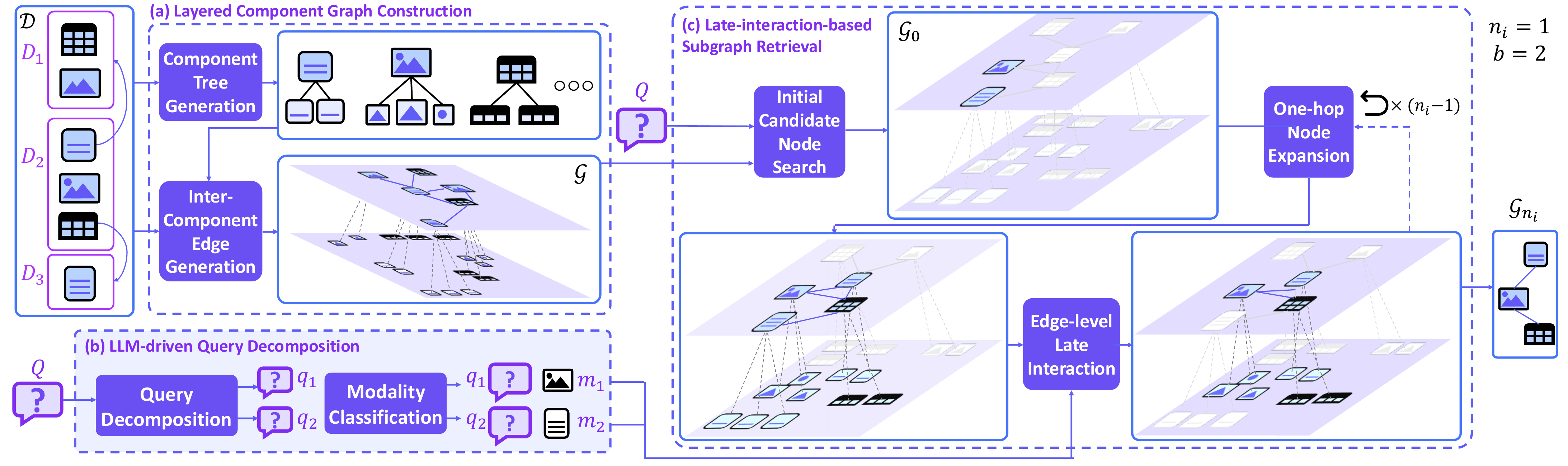
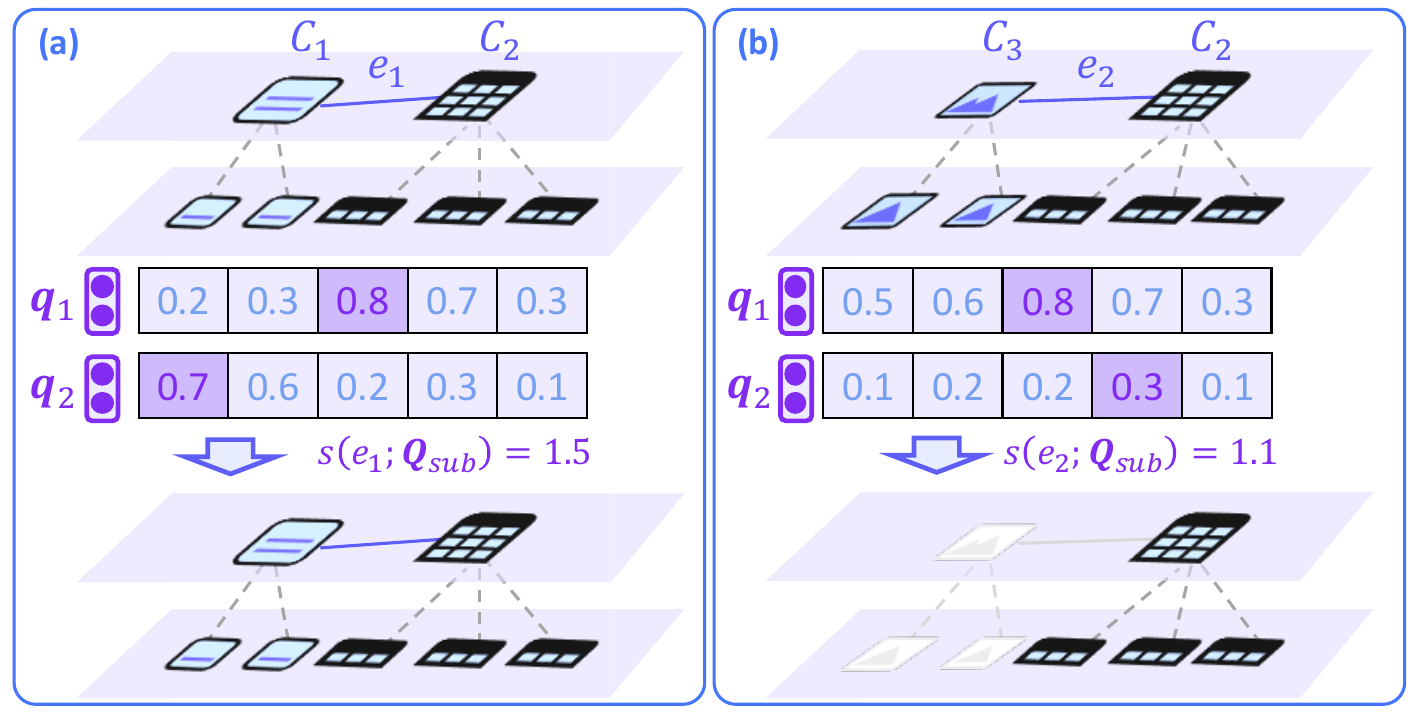
- No fine-tuning required: Uses pretrained multimodal embedders (MM-Embed/UniME/mmE5) and late interaction scoring to avoid storing edge embeddings while improving both precision and efficiency.
Motivation

Challenges of existing TextRAG and VisRAG pipelines: (a) text-only summaries can drop crucial visual cues; (b) coarse screenshot granularity dilutes relevant content; (c) missing structural links limits multihop reasoning.